WSo2 support patching in brief
WSO2 support system issues patches to fix defects that are found in product setups. This patching procedure needs to be methodically handled as the fix that you are applying should correctly solve the issue, it should not introduce regression, it should be committed to relevant public code base, it should be committed to support environment and validated that it correctly fit in with existing code base.
Patch Management Tool (PMT)
In an environment where you have large customer base and expects many clarifications daily, there are chances of developers missing certain best practices. Therefore a process that forces and reminds you of what need to be done while the process should be embedded to the system. WSO2 Patch Management Tool, PMT was built for above purpose.
In the above process, we also need to maintain a database of patch information. In WSO2 support system, applying a patch to a server involves a method which ensures that a new fix is correctly applied to the product binaries. This patch applying procedure mainly relies on a numbering system. This means every patch has its own number. Since we support maintenance for many platform versions at the same time, there are parallel numbering systems for each WSO2 Carbon platform version. All above data should be correctly archived and should be available as an index when you need to create a new patch. PMT facilitates this by being the hub for all patches. Any developer who creates a new patch obtains the patch number for his work from PMT.
WSO2 support system involves many developers working parallel in different or same product components, based on the customer issues they are handling. In such space, it is important to have meta data such as the jar versions that are patched, commit revisions, patch location, integration test cases, integration test revisions, developer/QA who worked on the patch, patch released date to be archived. These information are needed at a time of a conflict or an error. PMT facilitates an environment to capture these information.
So as described in above the main purposes of PMT are managing patching process, generating patch numbers, archiving patch metadata and providing search facility. This was initially introduced and designed by Samisa as a pet project for which Lasindu, Pulasthi helped with writing extensions as part of their intern projects and Yumani with QAing.
To cater the project requirements, WSO2 Governance Registry was chosen as the back end server with WSO2 user base connected via WSO2 IS as the user store and MySQL for registry. Later WSO2 User Engagement Server was integrated as the presentation layer, using Jaggery framework to develop the presentation logic. From WSO2 G-Reg, we are using the RXT, LifeCycle and handler concepts, search/ filtering facilities and governance API. From WSO2 UES we are using webapp hosting capability. WSO2 IS is LDAP user store.
In the proceeding sections I will briefly describe how PMT evolved with different product versions, absorbing new features and enhancements.
First version in wso2greg-4.5.1
PMT was initially designed on G-Reg 4.5.1 version. Using the RXT concept, an artifact type called patch was built. This is to capture all metadata related to a patch. It also defines a storage path for patch metadata, a listing view which provides a quick glance on the existing patches. Few important parts of the rxt is discussed below;
Our requirement was to capture data on JIRA's basic information, client/s to whom its issued, people involved, dates, related documentation and repositories. So the RXT was categorized into tables as Overview, People Information, JIRA Information, Patch Information, Test Information and Dates.
<content>
<table name="Overview">
</table>
<table name="People Involved">
</table>
<table name="Patch Information">
</table>
<table name="Test Information">
</table>
<table name="Dates">
</table>
</content>
Each above <table> has the attributes related to them. Most of these were captured via <field type="options"> or <field type="text">
Above RXT (patchRXT) was associated to a Lifecycle to manage the patching process. Patch LifeCycle involves main stages such as Development, ReadyForQA, Testing, Release. Each above state includes a set of check list items, which lists the tasks that a developer or QA needs to following while in a particular Lifecycle state.
Sample code segment below shows the configuration of the 'testing' state:
<state id="Testing">
<datamodel>
<data name="checkItems">
<item name="Verified patch zip file format" forEvent="Promote">
</item>
<item name="Verified README" forEvent="Promote">
</item>
<item name="Verified EULA" forEvent="Promote">
</item>
<item name="Reviewed the automated tests provided for the patch">
</item>
<item name="Reviewed info given on public/support commits" forEvent="Promote">
</item>
<item name="Verified the existance of previous patches in the test environment" forEvent="Promote">
</item>
<item name="Auotmated tests framework run on test environment">
</item>
<item name="Checked md5 checksum for jars for hosted and tested" forEvent="Promote">
</item>
<item name="Patch was signed" forEvent="Promote">
</item>
<item name="JIRA was marked resolved" forEvent="Promote">
</item>
</data>
<data name="transitionUI">
<ui forEvent="Promote" href="../patch/Jira_tanstionUI_ajaxprocessor.jsp"/>
<ui forEvent="ReleasedNotInPublicSVN" href="../patch/Jira_tanstionUI_ajaxprocessor.jsp"/>
<ui forEvent="ReleasedNoTestsProvided" href="../patch/Jira_tanstionUI_ajaxprocessor.jsp"/>
<ui forEvent="Demote" href="../patch/Jira_tanstionUI_ajaxprocessor.jsp"/>
</data>
</datamodel>
<transition event="Promote" target="Released"/>
<transition event="ReleasedNotInPublicSVN" target="ReleasedNotInPublicSVN"/>
<transition event="ReleasedNoTestsProvided" target="ReleasedNoTestsProvided"/>
<transition event="Demote" target="FailedQA"/>
</state>
As you may have noticed the Lifecycle transitionUI in which user is given an additional interface in between state changes. In above, on completion of all check list items of the testing state and at the state transition, it pauses to log the time that was spent on the tasks. This information will directly update the live support JIRA and is used for billing purposes. The ui-handlers were used to generate this transition UI dynamically. Later in the cycle wee removed it when Jagath and Parapran introduced a new time logging web application.
The various paths that the patch might need to be parked given the environment factors, we had to introduce different intermediate states such as 'ReleasedNotInPublicSVN', 'ReleasedNoTestsProvided'. <transition event> tag was helpful in this. For example a patch can be promoted to 'released', or 'ReleasedNotInPublicSVN' or 'ReleasedNoTestsProvided' states or it can be demoted to FailedQA' states using <transition event> option.
Performance Issues in G-Reg 4.5.1
When compared with the low concurrency rate we had at the time, the response time was high while PMT is hosted in G-Reg-4.5.1. This was even observed in JIRA details page. Suspect was that a *social* feature which pops up worklist items in the UI, as per the design at the time, use to run at each page refresh. Also there was a delay when working with Lifecycle state checklist items too.
Migrated to G-Reg 4.5.3
Considering the performance problems and some of the new enhancements to RXTs, PMT was migrated to G-Reg 4.5.3. Migration process was very smooth; there were no database schema changes. We were able to point to the same database that was used earlier. Above issue was solved in new version of G-Reg.
There was also RXT related enhancements, where we could now have a pop-up calender for dates opposed to the text box in the previous version.Filtering; In the earlier version patch filtering was done through a custom development which we had deployed in CARBON_HOME/repository/component/lib. But in the new version this was an inbuilt feature. There were also enhancements in G-Reg's governance API that we could laverage in generating reports and patch numbers.
Moving historical data to live environment.
Prior to PMT, there was a use of Google spreadsheets to maintain patches related metadata. Since PMT is being used as repository to 'search' patches and related information; it was time to move old data also into PMT. All the previous data that were captured in 6 different spread sheets were moved to PMT. This involved data analysis, since some of the field names were different from spreadsheet to spreadsheet and from spreadsheets to PMT. After background adjustments, Ashan from support team moved the historical data by retrieving data from spreadsheets using dataservices and writing them to PMT using a RemoteRegistry API [2 -svn location of gov-api code].
This added 900+ patches to the live system and also effected performance as below. This was done using data service to get data from spreadsheets and a java client to add them to PMT [attached].
Looking for new avenues
Scalability:
With the patch database becoming larger by data migrated from archives, as well as PMT being used daily by rotational support teams; there arose an issue where you get an unpredictable stability issues. PoolExhaustedException was one of which that was reproducible when the loaded database is idle for couple of days[1].
After checking into details, leading G-Reg engineers Ajith, Shelan proposed some changes to data-sources configuration which helped.
Introduced 'removeAbandoned' and 'removeAbandonedTimeout':
<removeAbandoned="true"
removeAbandonedTimeout="<This value should be more than the longest possible running transaction>"
logAbandoned="true">
Updated 'maxActive' to a higher value than the default value of 80.
<maxActive>80</maxActive>
But we had couple of more problems, we noticed that it the response time for listing the patches is unreasanably high. Some of the reasons that were isolated with the help of Ajith was that the default setting for versioning which was set to true. In G-reg Lifecycle related data used to be stored storing as properties, so when <versioningProperties>true</versioningProperties> is set, it massively grows the REG_RESOURCE_PROPERTY and REG_PROPERTY tables with the resource updates.The patch LifeCycle (contains 20 check list items) , when one patch resource going through all the LC states, it is adding more than 1100 records to REG_RESOURCE_PROPERTY and REG_PROPERTY when versioning is set to true.
Summary of Ajith's tests;
Versioning on:
Adding LC : 22
One click on check list item : 43
One promote or demote: 71.
Versoning off:
Adding LC : 22
One click on check list item : 00
One promote or demote: 24.
As a solution following were done;
1) Created a script to delete the unwanted properties
2) Disabled the versioning properties, comments and Ratings, from static configurations in registry.xml [2 - https://wso2.org/jira/browse/REGISTRY-1610]
<staticConfiguration>
<versioningProperties>false</versioningProperties>
<versioningComments>false</versioningComments>
<versioningTags>true</versioningTags>
<versioningRatings>false</versioningRatings>
<servicePath>/trunk/services/</servicePath>
</staticConfiguration>
There was also another bug found related to artifact listing. There is a background task in G-Reg to cache all the generic artifacts. That help us to reduce the database calls when we need to retrieve the artifacts(get from cache instead of database).In G-Reg 4.5.3 it doesn't work for the custom artifacts such as patchRXT and it only works for service,policy,wsdl and schema.This issue was patched by the GReg team.
Process Validation:
With increase of number of users daily basis, fastening link with the process became very important. The existing UI at that time was G-Reg management console, but our requirement was to validate Lifecycle events with data in RXT.
Jaggery based web application and GReg upgrade
GReg migration to 4.6.0 version was done by Parapran to overcome above issues which was known and fixed in new GReg and a new jaggery based web application was developed by support intern at the time, Nazmin as per Yumani's design and Jagath and team's valuable feedback.
The intention of the new PMT application was to provide a very user friendly view and to assure the developers of the patches follow all necessary steps in creating a patch. For example a developer cannot proceed from the 'development' state if he has not updated the support JIRA, public JIRA, svn revision fields. If he selects to say automation testing is 'Not possible' he has to give reasons. If he has done tests, he has to give the test commit location etc. Yes, we had occasional disturbed use cases. Special thanks to Paraparan and Ashan who fixed these cases with no time.
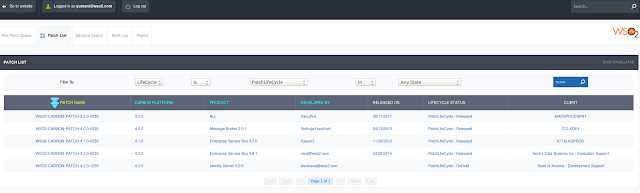
Image 1: Patch Listing
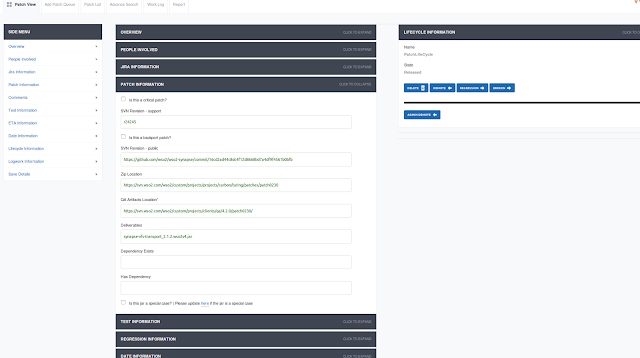
Image 2: Patch Details
This application was highly appreciated by the users as it allowed auto generation of patch numbers, pre-populated data for customer projects, users, products and versions etc. As promised it duly validates all mandatory inputs by creating a direct bind to user activities.
Today, the application has been further developed to capture various patch categories such as ported patches, critical patches, preQA patches. GReg based life cycle is also further developed now to cator pre Patch creation and post patch creation tasks. It was Inshaf who implemented these enhancement. We are also working on new features such as updating customers with the ETAs for patches based on three point estimation, looping leads and rigorously following-up in delays.
The application was also deployed in an HA setup by Chamara, Inshaf and Ashan for higher scalability, where the back-end GReg is clustered to 4 nodes fronted by Nginx which is sitting between the client application and the BE. We have about 100+ engineers accessing this application daily with around 15 concurrency for adding patches to patch queue, generating patch numbers, progressing patches through patch life cycle and searching for meta information.
Additionally the PMT database is routinely queried for several other client programs such Patch Health clients, where we generate reports on patches which are not process complete, Service Pack generation where the whole of database is read to extract patches belonging to a given product version and its kernal, Reports for QA at the time of the release testing where they seek for use cases patched by the customer. Most of these client applications are written using governance API.
PMT is a good example of a simple use case which expanded to a full scale system. It is much used in WSO2 support today and we extended it to have many new features to support the increasing support demands. We have been able to leverage Jaggery framework to all UI level enhancements. Governance registry's ability of defining any type of governance asset and customizable life cycle management feature pioneered the inception of this tool and helped in catering the different data patterns that we wanted to preserve and life cycle changes that needed to be added later according to the changes in the process. We were able to add customized UIs to the application with the use of handler concept in GReg. When the front end jaggery web application was introduced, we had a very seamless integration since the back-end could be accessed via governance API. Increasing load demands were well supported by Carbon clustering and high availability concepts.





